
How to Use Simon Dedupe
Simon Dedupe is currently an Alpha feature.Please reach out to your account manager to be added to the waitlist!
Entity resolution in Simon is meant to provide you with a first line of defense against dirty data, primarily focused upon single dataset normalization, standardization, and deduplication. It allows for flexible matching, providing options for both deterministic and probabilistic methods, whereas downstream identity resolution for CDP use cases is purely deterministic.
Cleanse, Normalize, and Dedupe Data
- Click Identity in the left-hand navigation bar. If you're new to Simon and haven't yet created your identity table, you will be on the Identity Table tab by default. If you already have an identity table, you will be on the Models tab by default. To learn more about Models, read on here.
- Click Select & Configure Identity Input Tables.
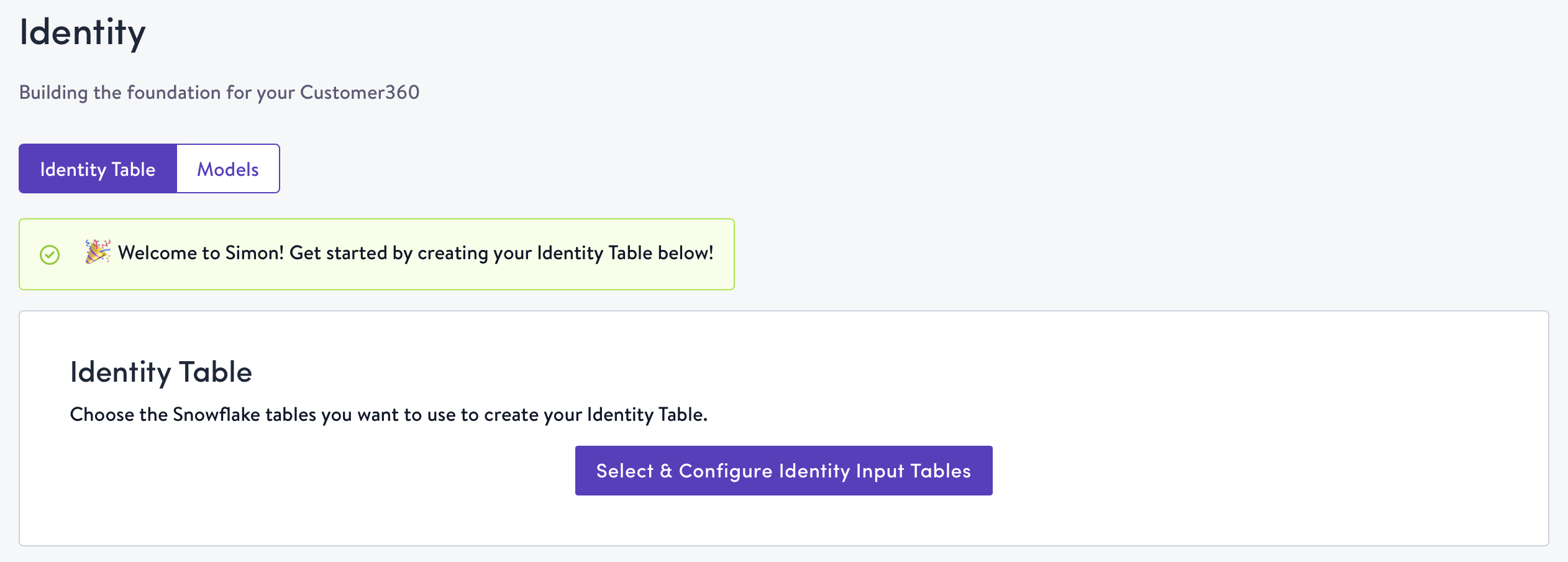
- Use the drop-downs to select the tables you would like to process via Simon Dedupe, then click Next. These drop-downs are populated by our direct connection to your Snowflake instance.
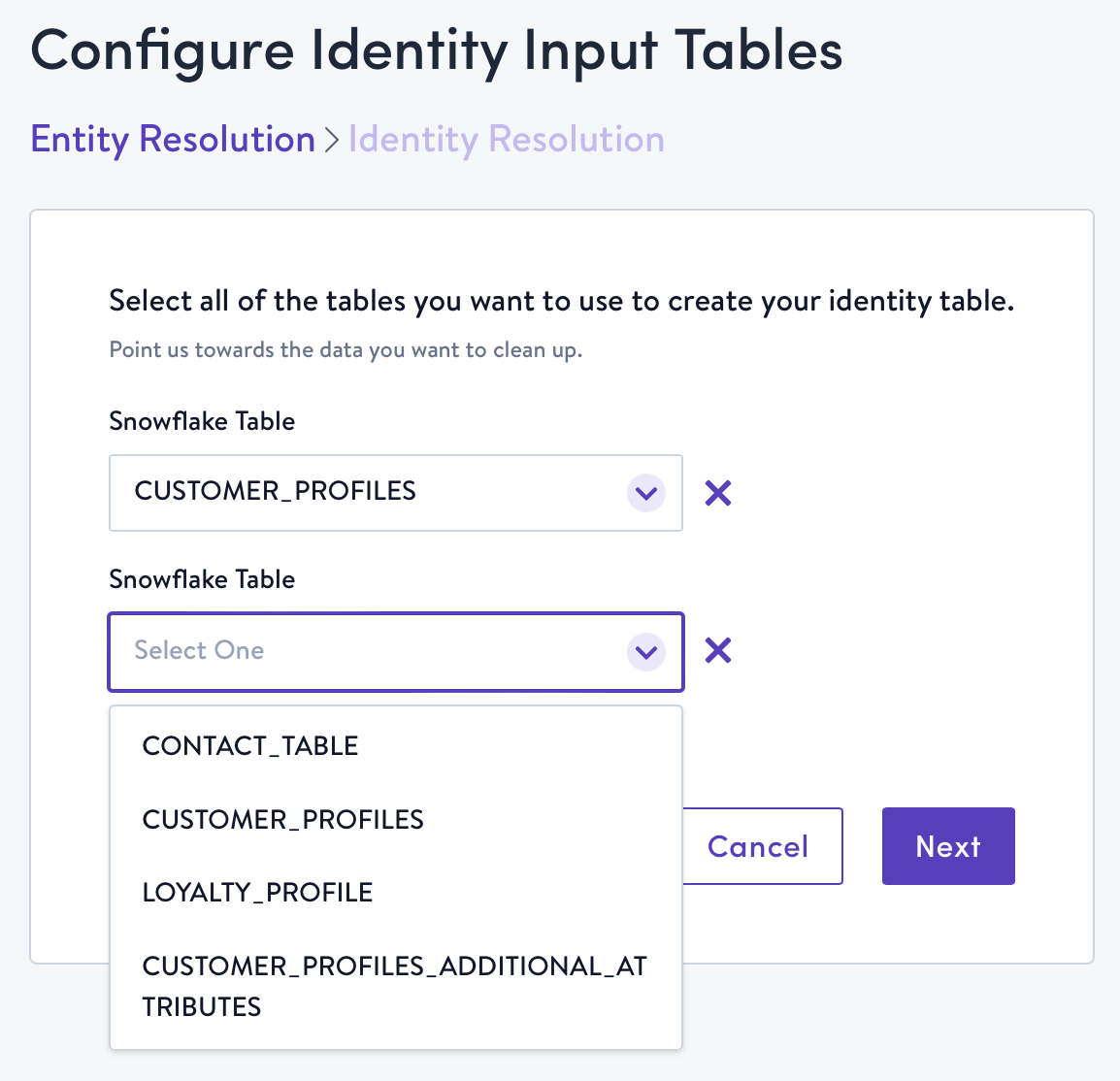
- Click Configure Table for each of the tables you selected to configure entity resolution rules.
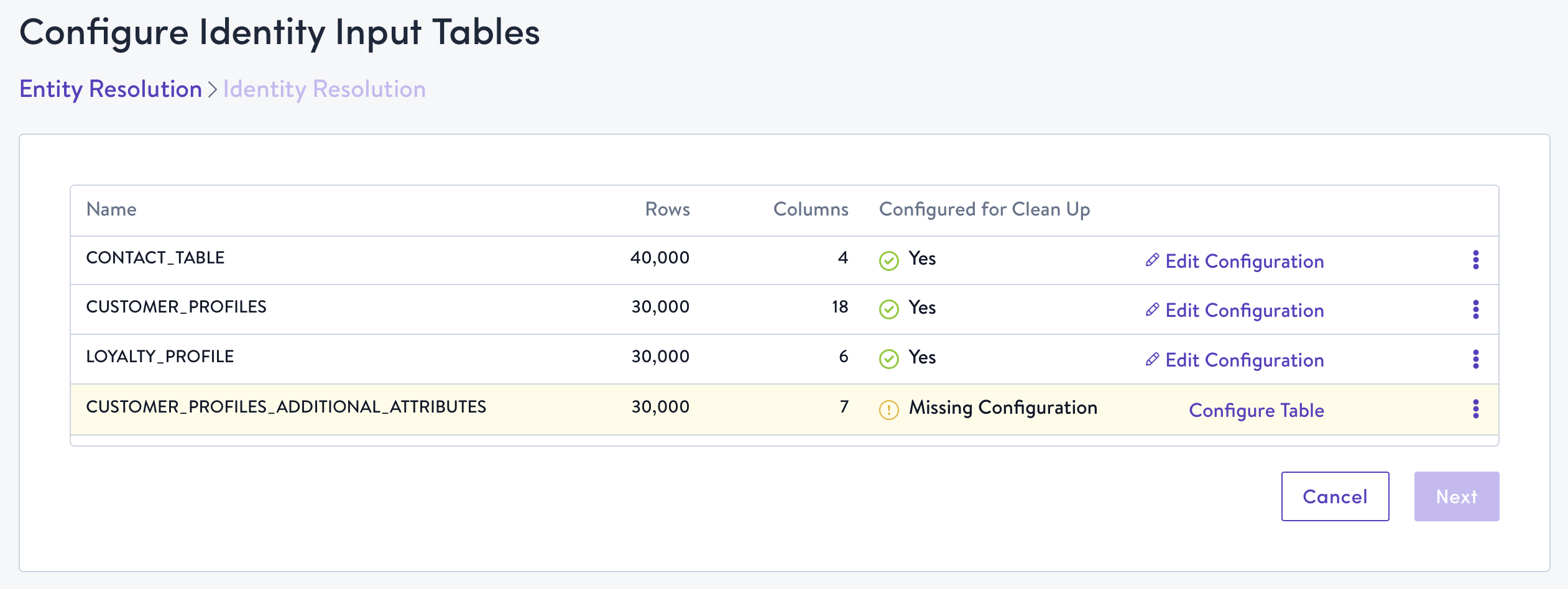
- Simon deploys several cleansing & normalization techniques to several fields that may be present in your source data in order to enhance the accuracy of Simon Dedupe, ensuring your data is consistently unified and ready to drive actionable insights and revenue growth. If fields that qualify for normalization are present in your source table, we will display them here. Select the fields you want to normalize by checking their boxes.
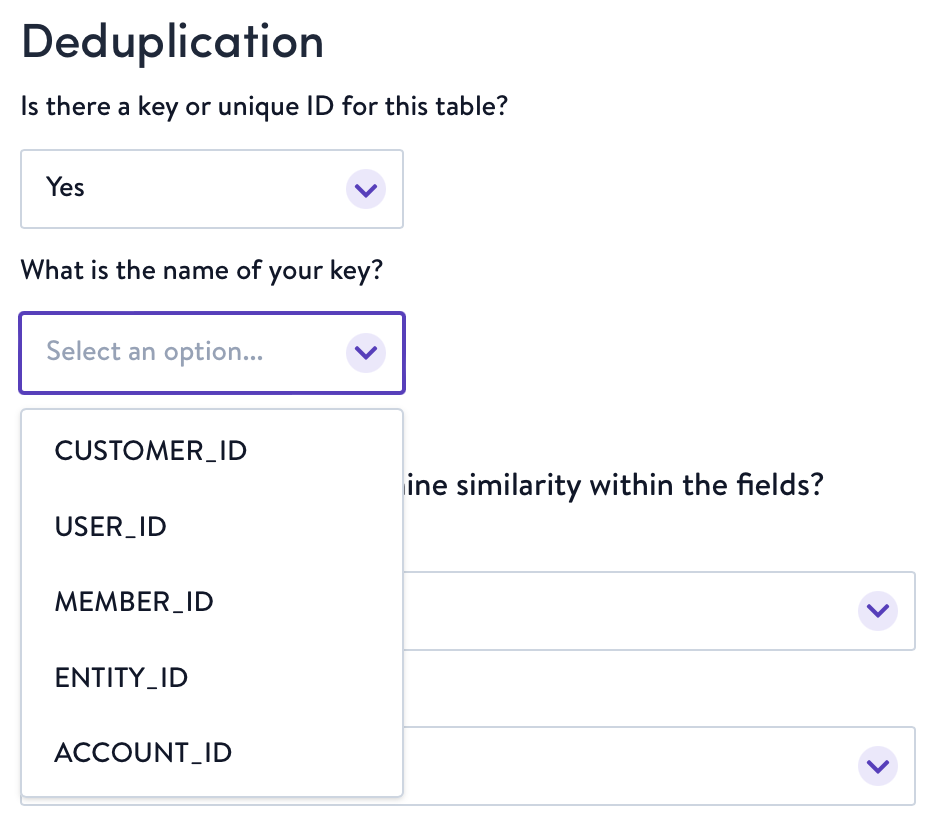
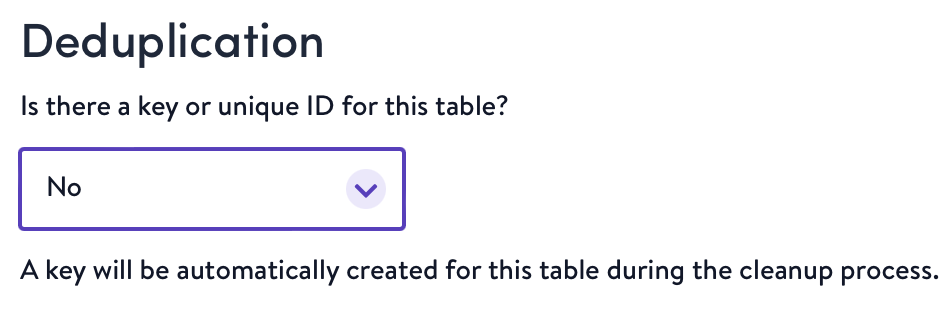
- After normalization comes deduplication. Select whether or not a primary key exists on the table you're configuring. If yes, we will ask you to specify it, and we'll use that to deduplicate profiles. If no, we will generate one for you.
- For each of the fields that were selected for normalization, select the comparison operator you want to be applied for determining how similar two records are to one another. For fields that are also channel identifiers like email address and phone number (e.g. these identifiers are being used to contact your customers), it's best to ensure an Exact match so that identifiers that belong to different customers don't get merged together. For fields that have a little bit more flexibility, you may want to select Phonetic or Fuzzy matches to account for slight differences in data (e.g. Rob vs. Bob, Street vs. Stret).

- Next, we'll ask how you want Simon Dedupe to calculate match probability using a weighted average of the similarity scores. This helps us identify potential duplicate records by calculating a match probability score based on key customer attributes. The more important the field, or identifier, the higher the weight should be.
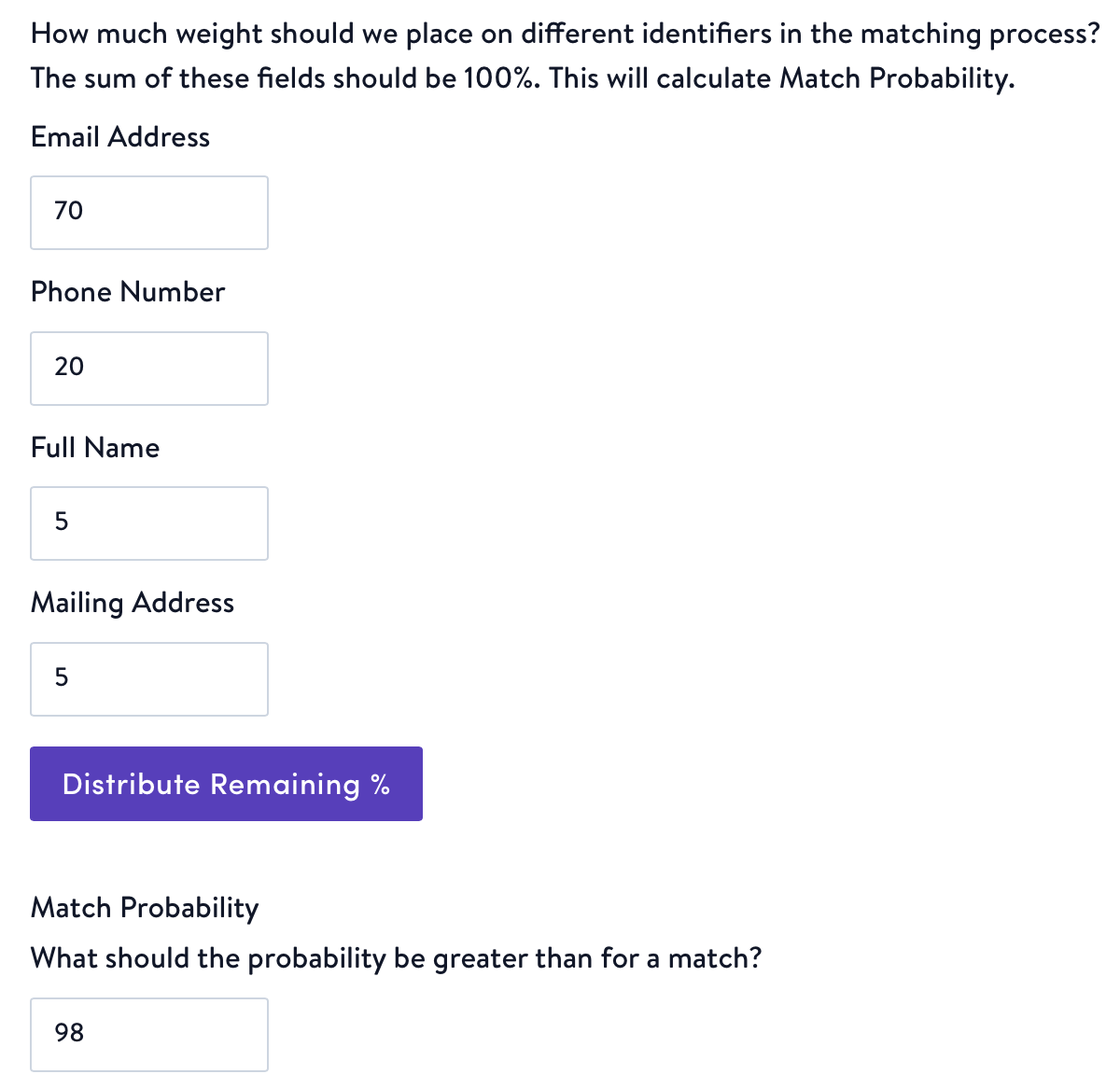
- Choose a Match Probability score. This is a crucial metric for determining whether two records refer to the same entity. Your goal is to maximize the number of correct identifications while minimizing errors.
How to choose a Match Probability score:Understand the Data Characteristics: Consider the nature of the data, including common errors or variations in data entry. For example, if the data often contains typos or different formats (like abbreviated names), a lower threshold might result in too many false positives.
Consider the Impact of Mismatches: Weigh the consequences of false positives versus false negatives. In some cases, like fraud detection, a false negative (not identifying a match) might be more detrimental than a false positive. Conversely, in customer service scenarios, a false positive (wrongly merging customer records) could lead to a poor customer experience.
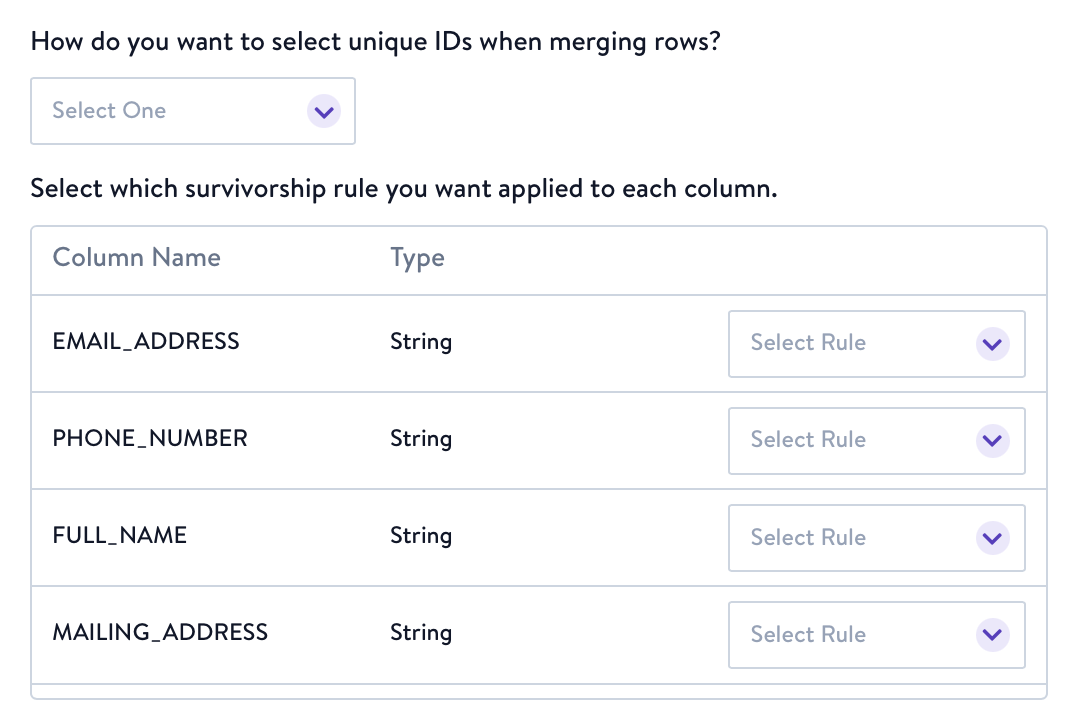
- Lastly, we'll ask you to define survivorship rules for each field. In the event that multiple records are deemed similar enough to merge into one record, you must choose which profile "wins" by selecting either the minimum or maximum value for the unique ID. Additionally, for each field you must select a survivorship rule to be applied.
Survivorship Rule Definitions:Newest Value
- This rule selects the value that appears most recently. Requires a timestamp to determine which value is the most recently updated value.
Oldest Value
- This rule selects the value that appeared first. Requires a timestamp to determine which value is the oldest.
Frequency
- This rule calculates the winning value as the one that's contributed by the most number of records. E.g. For the first name field, if I have 3 duplicate profiles in the table, with 2 records as Emily and 1 record as Em, the winning value for first name would be Emily because it appears more than Em.
Aggregation
- If an identifier has more than one value and Aggregation is chosen for the survivorship rule, then all unique values held within the attribute are returned in an ARRAY field.
Minimum Value
- This rule selects the minimum value. The minimum value is defined as follows for different data types:
- Numeric: MinValue is the smallest numeric value.
- Date: MinValue is the minimum timestamp value.
- Boolean: False is the MinValue.
- String: MinValue is based on the lexicographical sort order of the strings.
Maximum Value
- This rule selects the maximum value. The maximum value is defined as follows for different data types:
- Numeric: MaxValue is the largest numeric value.
- Date: MaxValue is the maximum timestamp value.
- Boolean: True is the MaxValue
- String: MaxValue is based on the lexicographical sort order of the strings.
- Click Save Table Configuration.
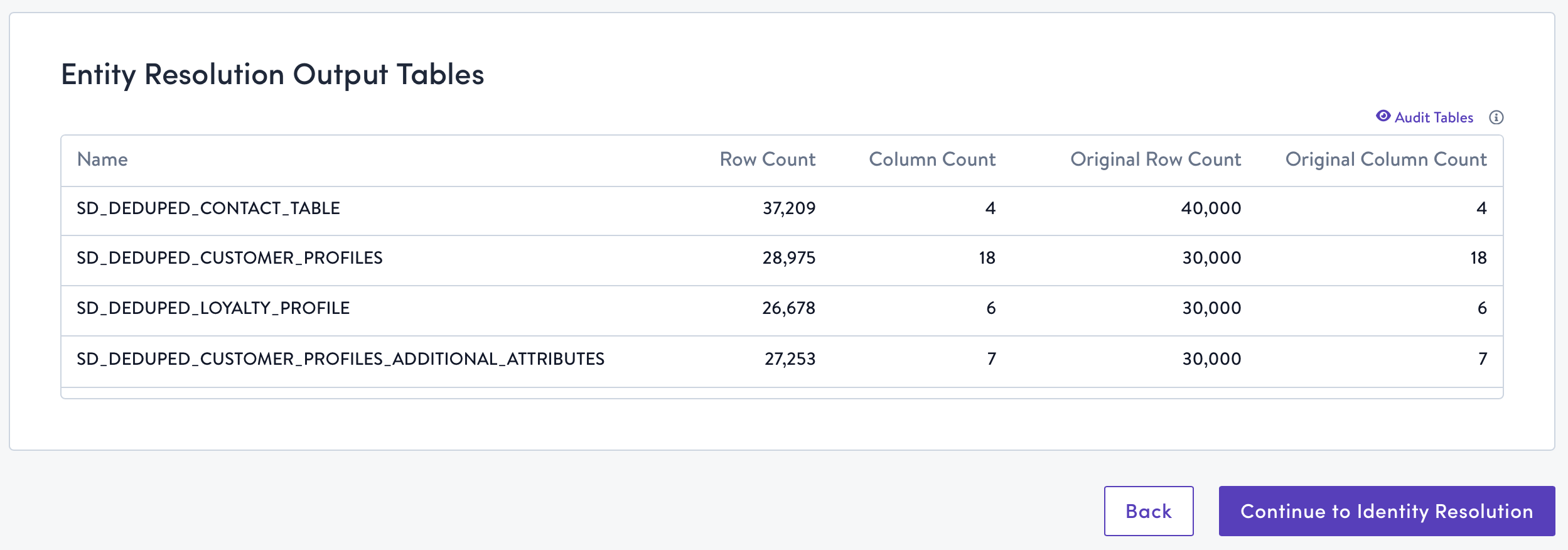
- When you're satisfied with the configurations for all of your input tables, click Normalize & Dedupe Tables.
Success!You're now ready to perform identity resolution with your cleansed, normalized, and deduplicated tables! See Simon Resolve for details, or click Continue to Identity Resolution.
Updated 9 months ago