
Managing Survivorship Rules
Contact your account manager to get started with Survivorship.
Survivorship ensures you're using the most accurate and up-to-date information when referencing customer data for personalization or analysis.
Why Survivorship Matters: A Real-World Example
Imagine a customer profile built from multiple sources—your eCommerce platform, CRM, and loyalty database. Each source has slightly different values for the customer's loyalty tier. One says "Gold," another says "Silver," and a third still shows "Bronze." Without clear rules, which one do you use?
Survivorship allows you to define logic like "always use the most recently updated value" or "aggregate all values." This ensures that your messaging reflects reality—for instance, addressing your high-value customer correctly as a Gold-tier member.
Overview
Survivorship rules determine which value to use when multiple sources supply the same field for a contact. In Simon, survivorship can be managed in two places:
- Schema Builder – Ideal for setting field-level rules when configuring or editing a single table.
- Data Hub – Best for auditing or bulk editing survivorship rules across many fields and tables.
Survivorship rules only apply to 1:1 contact propertiesSurvivorship rules are designed to resolve differences in 1:1 contact-level fields — like name, email, or birthday — where we want to keep a single, trusted value. For 1:many data like events (e.g., purchases, logins, messages), survivorship doesn’t apply, since these fields naturally store multiple values and don’t require a ‘winner.’ Instead, all relevant event records are preserved as part of the contact’s history.
Configure Survivorship in Schema Builder
Use the Schema Builder when adding or modifying a specific property table.
Steps:
- Navigate to Schema Builder from the left-hand nav.
- Click Add New and select Property Table as the table type.
- Choose your source table from the dropdown and define the Join Key.
- In the field list:
- For desired personalization fields, check the Content box.
- Optionally update the Content Alias if a different display name is preferred.
- Scroll to the bottom of the configuration page to find Survivorship Rules.
- Simon will set default survivorship rules based on the field's data type. You are welcome to change these default rules at any time, for any field. See Rule Definitions & Defaults Per Data Type at the bottom of the page for more details on the rules themselves.
- Each rule will apply whenever Simon detects conflicting values across sources.
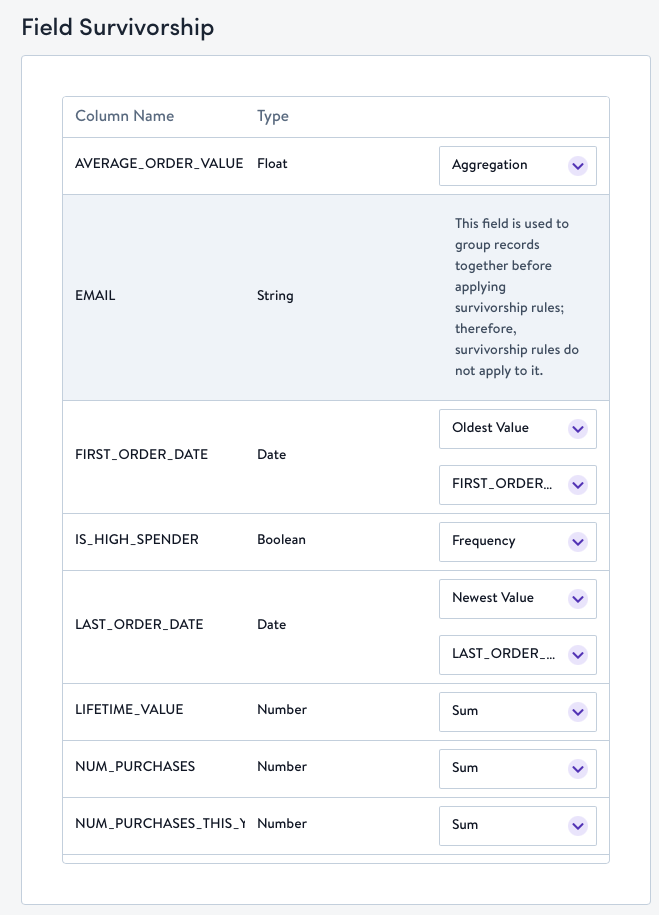
Use the Schema Builder when you're connecting a new table or updating the survivorship logic for one table at a time.
Manage Survivorship in Data Hub
Use the Data Hub for visibility into all survivorship settings and to update them in bulk.
Steps:
- From the left-hand nav, go to Data Hub.
- Use the search bar to locate a specific field or table, if desired.
- Click Edit Fields in the upper right corner.
- Click the expand icon to view and modify the survivorship rule for a field.
- To edit multiple fields, simply apply your changes across many fields.
- Click Save to apply updates.
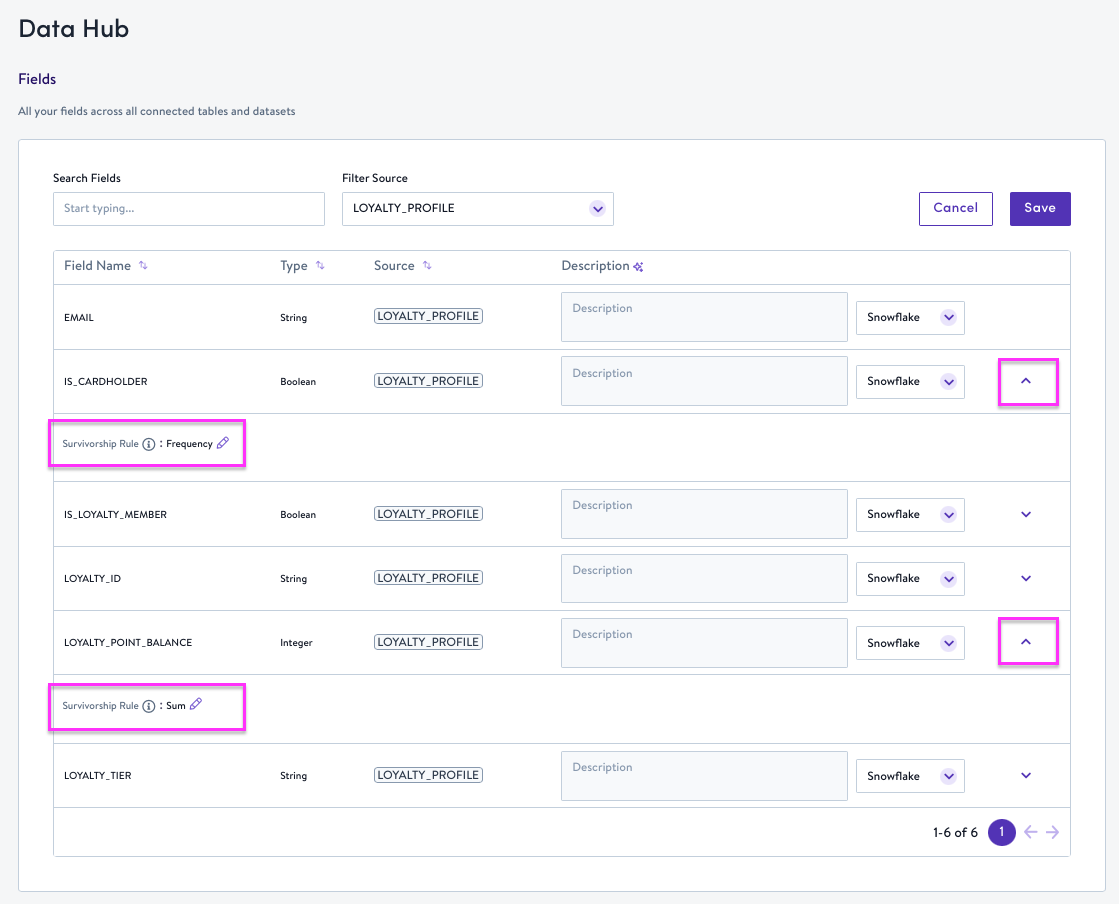
Data Hub provides a centralized way to audit survivorship rules across your instance.
Best Practices
- Set survivorship rules early—especially for fields used in personalization.
- Revisit survivorship rules periodically in the Data Hub to ensure they align with evolving data pipelines and priorities.
- Keep business stakeholders informed when changes to survivorship logic are made, as it may affect message content or segmentation.
- While the default rule for fields with a
NUMBERdata type is Aggregation, numeric values can also represent measurable behaviors or traits that are best understood cumulatively - such as total spend or number of orders. In this case, we recommend changing the default survivorship rule to SUM to ensure that valuable signal is stored cumulatively rather than in an array.
Rule Definitions
| Rule Name | Definition |
|---|---|
| Newest Value (aka Recency) | This rule selects the value within the attribute that appears most recently. Requires a timestamp to determine which value is the most recently updated value. |
| Oldest Value | This rule selects the value within the attribute that appeared first. Requires a timestamp to determine which value is the oldest. |
| Frequency | This rule calculates the winning attribute as the value that is contributed by the most number of records. E.g. For the first name field, if I have 3 duplicate profiles in the table, with 2 records as Emily and 1 record as Em, the winning value for first name would be Emily because it appears more than Em. |
| Aggregation | If an attribute has more than one value and Aggregation is chosen for the survivorship rule, then all unique values held within the attribute are returned in an ARRAY field. |
| Minimum Value | This rule selects the minimum value held in the attribute. The minimum value is defined as follows for different data types:
|
| Maximum Value | This rule selects the maximum value held in the attribute. The maximum value is defined as follows for different data types:
|
| Sum | This rule adds together all values across sources for this field. Best used for metrics like revenue, quantity sold, or time spent. |
Rule Defaults Per Data Type
| Data Type | Default Rule | Rationale |
|---|---|---|
INTEGER | Recency (if no timestamp available, fallback to Frequency) | Used for things like age, zip code, or loyalty tier. Most recent value is usually the most accurate. |
FLOAT | Recency (if no timestamp available, fallback to Frequency) | Commonly used for weight, balance, or scores. The freshest value tends to be most relevant. |
STRING | Recency (if no timestamp available, fallback to Frequency) | For names, addresses, job titles—last known value tends to be correct. |
BOOLEAN | Frequency | Example: opt-in/opt-out fields. The most frequent value across records is often correct and avoids flipping on/off with recency. |
TIMESTAMP | Recency (if no timestamp available, fallback to Maximum Value) | Always keep the most recent time-related event (e.g., last purchase, last login). |
DATE | Recency (if no timestamp available, fallback to Maximum Value) | Always keep the most recent time-related event (e.g., last purchase, last login). |
VARIANT | Recency (if no timestamp available, fallback to Frequency) | Since variants often represent flexible or nested data (e.g., JSON blobs), the most recent complete version of the data is typically the most accurate. Recency ensures you’re using the latest structure and values. |
ARRAY | Aggregation | Ideal for storing lists (e.g., product affinities, event history). Aggregating gives the full picture. |
NUMBER | Aggregation | Aggregation ensures that no potentially valuable data is lost, especially in cases where multiple sources might report different but valid numeric values (e.g. Age, Phone Number, etc.). |
Note about NUMBER fields:While the default rule for fields with a NUMBER data type is Aggregation, numeric values can also represent measurable behaviors or traits that are best understood cumulatively — such as total spend, number of logins, or clicks. In this case, we recommend changing the default survivorship rule to "Sum" to ensure that valuable signal is stored cumulatively rather than in an array.
Updated 8 months ago